Data Science Modeling and Importance in Featurization
No matter how much you want to ignore it but it is impossible to ignore the importance of data. The data is then examined, structured and contextualized to get the proper result. Data science is formed by blending many things together. These things include algorithm development, data interface, and technology. It helps in solving the analytically complex problems and the root of this formation is data.

As we all know that the data raw information flows in and are stored in the data warehouses of the company. Then the data mining is proceeded on the collected data making it possible for us to incorporate advanced capabilities. The main function of data science is to utilize the data in a unique way to generate business revenue.
Love what you read? Then grab a fresh piece of content right here.
{{cta('ff8f1d21-87b7-43c4-bcc4-3a1f1acc0329')}}
For processing data science, the most essential part is the data modeling. The modeling techniques are the most compensating process that has become the center of attention for the data learners. But, no matter how much you think, things are not that easy and simple. It is not just about applying functions from one package class and applying it to the available data. There is more to it than that.
The Data science modeling depends on the evaluation of the specific model. You need to make sure that the data is robust and reliable in nature before proceeding further. Not only this, but data science model is also linked with the information creating a feature. Apart from so many things, the data modeling also requires some process that guarantee that the data used is properly proceeded giving out a better and more consistent result.
Also Read: Data Science as a Service (DSaaS) : Anayzing Data Better
Big Data is all about looking out for latest and interesting trends through various processes like Machine learning, statistics, and another numeric method. However, it really wants to have a better insight that you must use the predictive modeling technique. This technique is linked with the Data Featurization.
What is Data Featurization?
In all this, you might be wondering what actually featurization is. To make it easy, it is a process that converts the nested JSON object into a pointer. It becomes a vector of scalar value that is the basic requirement for the analysis process.
Well, this single definition can be translated in various ways. Here are the set of meaning behind this statement.
- JavaScript Object Notation (JSON) is a lightweight format that for the data set through which machines can easily write and read. The main reason behind using JSON is that it can easily and strongly interact with different languages (platform) such as JavaScript, R, Python, etc. The software that is used to interact with the stored data is mainly for the data that is influenced JSON.
- You all might have learned the term scalar in physics. It is a 1-Dimensional physical quantity. In the data featurization, it is used for a computational framework to stored and recall a unit of measure. The point to remember is that it only store value in a single form such as ‘blue’, ‘1’, etc.
- In the Linear Algebra tradition, the term vector was widely used. The collection of several of elements is known as vector space. For example, [2, 5, 7, 9].
With the help of vectors of scale, it is possible to perform statistical and computational work that cannot be done by raw data.
Also Read: 6 Reasons to choose R programming for Data Science
Robust Data Model
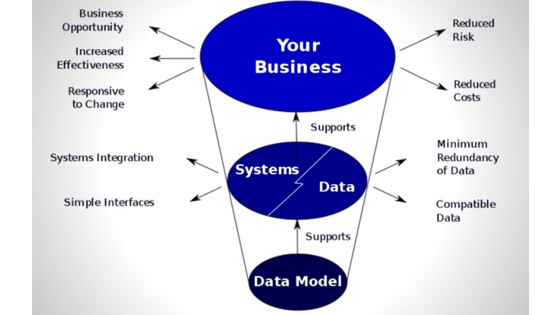
While talking about robust models, they are valued for the formation of the production. There are many properties covered by such a model. You will get a good performance that will be based entirely on the metrics values. However, a there is much time when the single metric value can be completely wrong or misleading. Also, the performance of the model as per different aspect is difficult to proceed in such a case. This often happens if the system has a classification problem.
Apart from this, you can experience a good generalization through this robust model. This simply means that the model works appropriately and relevantly with the datasets and also on the one they are not trained for.
On talking about the aspect of data science modeling, you simply can’t miss out the sensitivity analysis. It is used to test the robustness of the model through essential modes that guarantee better results. In this condition, if we change the input value of the model then the result will be changed significantly. However, this things can’t work of it changes value like this because robustness is all about stability.
Another aspect that is as important as sensitivity is interpretability (which is not possible every time). As the name suggests, it is about how the result of the model is interpreted. However, there are many models that are considered as black boxed due to their difficult name of being interpreted. As a result, it is recommended to use a model which can be easily interpreted. This severely follows if the output of that model needs to be in a secure state.
Also Read:What is Hadoop and how it changed Data Science
The Vision of Featurization is Better Data
There are times when the vision or understanding of a model can be used to highlight the improvement that must be incorporated in the future model to elevate its efficiency. Also, if the database transaction has extra data like transactions type then it can be extremely helpful. This will make the association between frequency and typical amount easy to determine. The integration on a new data set requires a lot of additional work for the linking and cleaning. After which the data is refined in the featurizing.
Also Read:5 Key Skills Data scientist must posses for Big Data Projects
Value in Featurization
There are different process to add the value to the featurization process. They are as follows
As mentioned about, featurization is used to bridge the gap between linked and cleaned format with the format that provides predictive modeling algorithms and statistical tests that can be used on the data.
With the help of featurising, it is easy to go through the problems in a client project by various means.
- It helps in developing tools that can be used on projects and save the extra efforts while doing so.
- You can use the optimization process on the use-case that will be called many times However, on investing in the specialized and the hardware solution, it is easy to understand that it be helpful in remunerating extra shares on the projects.
- You can even collaborate in an efficient manner. Due to the consistently this system provide, it allows to easily pick up the work from where it is left. Also, it is easy to determine the output through strategies and analysis that make the data more abstract.
If you are using the predictive analysis approach then the featurization becomes the most essential and impactful work to proceed with. You can easily get a vision about the data and the modeling.
Also Read: 4 Ways Big Data Automation is changing Data Science
How to Accomplish Featurization?
If you desire to build a model with maximum potential then it is necessary to extract all the information of the data features. There are many ways to obtain that. You can use this anywhere, however, you will require the option of data cleaning. This option will help in eliminating the problematic and correcting the data points, removing noisy variables and filling up the missing values.
However, Normalization is required before suing variable in data modeling. It will ensure that the variable values are range appropriate that can be accomplished through the linear transformation. However, the method of normalization is also used to turn the variable in the feature form after cleaning it up.
In order to aid featurization, another process sued is Binning. This helps in the creating of nominal variables that can break into the binary features used in data modeling.
Then there is a reduction method of dimensionality that helps in shaping the feature set. This creates Meta features or features created by linear combination. It expresses the information as shown by the fewer dimension.
Also Read: Artificial Intelligence Vs. Machine Learning Vs. Data Science
Apart from this, the data science attributes do more than just creating the value of the raw data. As mentioned above points are just the bit and pieces of featurising data modeling. However, it requires ample learning and proper metrics to study the data. Data modeling is an easy branch but it still needs to be mastered properly that can be beneficial for the company. It may take some time but with an easy robustness method, it will be a cakewalk.
Got a project that requires Data Modeling? Then reach out to us for a consultation.
{{cta('a2dc9455-b0dc-41c6-877f-113a5762766d')}}