

Things to take care of when supporting iOS 13 Dark Mode in your app
Apple introduced Dark Mode to macOS with macOS Mojave and since then developers and users alike had been pinning for this in iOS as well. And...
4 min read
One of the most powerful tools that are used for the performance of art is Data science is statistics. If we go in terms of a data science then you need to understand that it is a mathematical aspect that helps in analysing the information. Sometimes, bar charts are used for the analysis for the data that is on high-level. But it is far different when it comes to statistics. We can actually operate that information in a targeted and information-driven manner. Hence, the mathematical formula can help you to understand the conclusion in a better aspect without depending on guesses.
You can say that it is a deeper form of data that can obtain a perfect insight into data. You can tell the structure of data and also the ways to optimize it as per the techniques of data science. Here are the main concepts that data scientists much known about statics to have an efficient result.
This is one of the most used concepts on the statistics for the whole data science concept. If anything, it is the first method that will pop into your mind while applying statics on a dataset. It will also incorporate variance, bias, median, mean, and percentiles. In addition to this, it is easy to understand than other methods and more easy to implement.
You can take an example of a box lot where the minimum and maximum value will be marked up. On top of that, it will have first and third quartile and in the middle of these, there will be a median. We will median in place of mean due to its robust nature when it comes to outlier values. Then, 25th first percentile will be the first quartile and 75th will be the third percentile. On the other hand, upper and lower values will be represented with minimum and maximum data range.
Now, why a box plot?
You can try your chunk of data to see where you stand.
If you are familiar with probability then you might know that it is possible to plot on probability as per the occurrence of qualified range. In simple words, the range in the data science will be 0 and 1 which means that 0 represents no occurrence whereas 1 will work as an occurrence. Hence, as a result, probability distribution will be the one where the possible value is characterized in the probability. It will be represented in the form of a graph.
These are divided further as well but these three are the most essential factor for the division. It will depend on the value of the data that can easily interpret the variable on a categorical level with the help of uniform distribution method. Whereas there will be many algorithms for the Gaussian distribution while in the Poisson, we can select the algorithm and take special care of data for our spatial speed variation.
If you understand the failure of Frequency statistic then you can understand Bayesian static on a high level. When we say frequency then our mind will automatically pop to the word probability. It will analyze the occurring of events and extracting probability with prior data to understand this information.
The best thing about Bayesian statistics is that evidence will be taken under consideration to obtain accurate idea. The formula used for this probability is;
P (H|E) = [P (H) * P (E|H)]/ P (E)Here,
P (H|E) = Posterior probability of H that is given as the evidence
P (H) = prior probability
P (E|H) = Likelihood of the evidence E if the hypotheses H is true
P (E) = Priori probability that the evidence itself is true
These value can easily explain out the prior data probability as compared to the likelihood. This layout gives out the perfect set of value for future data. Also, this is used for the frequency analysis that shows the accurate data with statistics.
The sigma six, data science, business intelligence and many more are a part of a business. You can say that it is the piece cut out from the same polygon with the help of certifications, projects, vocabularies and tools. However, the main focus of these is to reduce the cost and give maximum revenue with accurate results.
The style of each of the statistics value might be different with the several outcomes of effective with management practices. It helps in refreshing the data and management due to the utilization of the data science concepts. There is also K-Nearest Neighbor Algorithm that can be used for determination of the data.
Apart from this, statistics is full of such short technique as per the values and dataset. But the formula or data will be determined by seeing what we are expecting from that particular set. Hence, you need to have an insight in reference to the smallest part for abstraction or manipulation on an easier level. Hence, it is essential to have a statistical analysis that can put you on a better approach path.
Need help with new tech implementation? Get in touch
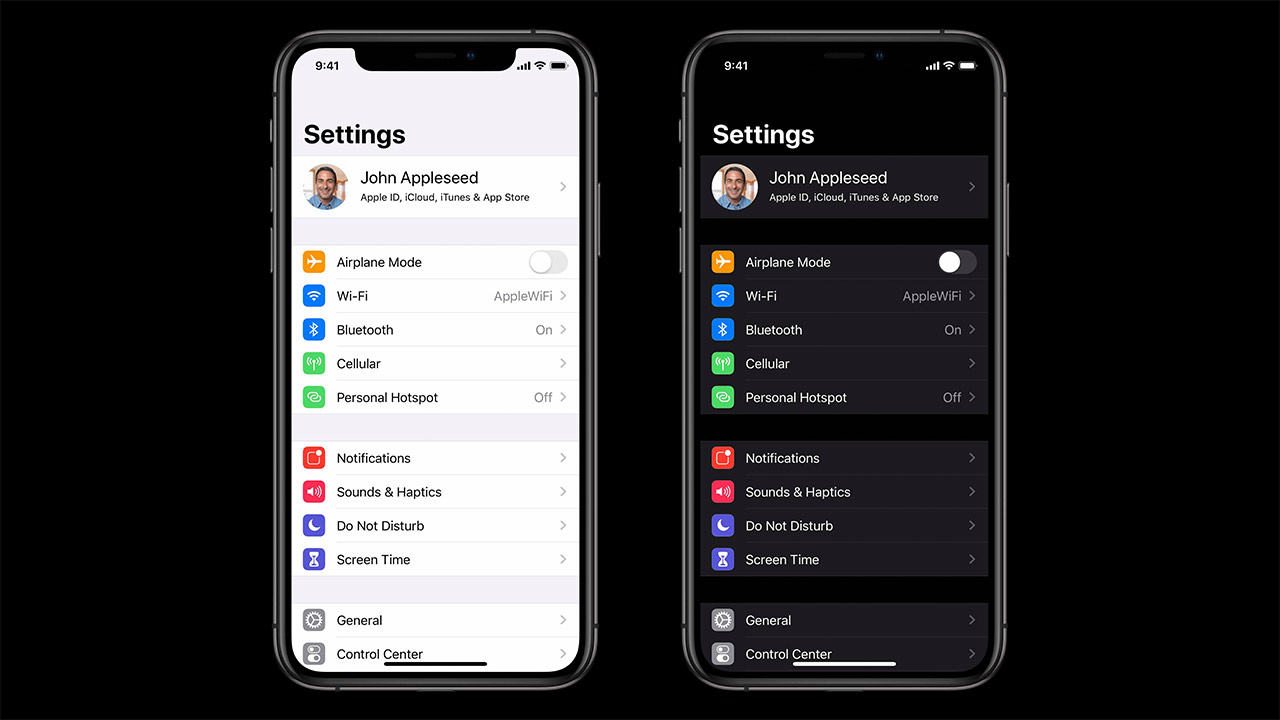
Apple introduced Dark Mode to macOS with macOS Mojave and since then developers and users alike had been pinning for this in iOS as well. And...

The rapidly changing business environment calls for all the companies to take necessary action to streamline and expedite their operations. This is...

It's safe to say that the smartphone has taken over our lives. Majority of us now use smartphones to carry out small, simple tasks from waking up in...